C’est toujours un peu dangereux de jouer les Madame Soleil en essayant de deviner les tendances de développement d’Internet pour les années à venir. Mais pourquoi pas? Cela donne en tout cas l’occasion de faire le point sur les développements marquant de 2009.
Le téléphone portable est en train de devenir le mode d’accès le plus important à Internet
Les statistiques montrent que le téléphone portable est devenu l’outil de communication le plus diffusé. L’Union Internationale des Télécommunications estime qu’à la fin de 2009, il y 4,6 milliards de souscriptions à un service de téléphonie mobile. Bien entendu, les téléphones portables permettant l’accès à Internet ne sont pas majoritaires: actuellement, le taux de pénétration est de 9,5 téléphones portables avec accès à Internet pour 100 habitants.
http://www.itu.int/ITU-D/ict/material/Telecom09_flyer.pdf
Le téléphone portable présente de nombreux avantages: léger, multi-fonctionnel, personnel (en Occident en tout cas), bénéfiant d’une large couverture réseau, bon marché à l’achat (moins à l’usage). La génération des smartphones en a fait un appareil permettant l’accès à Internet, un accès qui ne se limite pas à la consultation, mais aussi à l’écriture et à la participation aux réseaux sociaux. De fait, le téléphone est devenu un média en soi, avec ses propres modèles éditoriaux et ses règles de fonctionnement. Brièveté, fugacité et alertes. De plus en plus de sites ont une version pour téléphones mobiles. De nombreux producteurs d’information prennent en compte ce canal. L’information via le téléphone est aussi très liée à la localisation, ce qui redonne un nouveau souffle au concept de réalité augmentée. Finis les sacs à dos et les lunettes 3D, qui sont restés à l’état de prototype. Il suffit de sortir son téléphone pour en savoir plus sur le lieu où on se trouve … à condition d’avoir la bonne application. Le foisonnement des applications, c’est sûrement la maladie d’enfance des téléphones. Mais on a aussi connu ça sur les PC. La nature de l’information disponible grâce au téléphone peut se résumer avec la locution latine “hic et nunc” qui signifie ici et maintenant.
Les réseaux sociaux vont arriver dans leur phase de maturité
Il est probable que les réseaux sociaux vont arriver dans une phase de maturité dans laquelle les usages pourront se fixer. On a connu ce phénomène avec les blogs. Après une phase inflationniste où chacun a créé son blog pour dire tout et rien, le blog a trouvé sa vitesse de croisière. Il est maintenant bien intégré dans l’arsenal des communicateurs et prend une place toujours plus grande dans le paysage informationnel où il remplace souvent les listes de communiqué de presse. Des sites comme celui de la Maison Blanche ou du 10 Downing Street ressemblent maintenant à des blogs. Une firme comme Google en a fait son principal outil de communication. Les blogs actuels n’offrent pas nécessairement la possibilité de commenter. Ils constituent un nouveau format, plus accessible au grand public.
Pour l’instant, les réseaux sociaux sont encore dans la phase où tout le monde veut s’y mettre et personne ne sait comment les utiliser. Il y a beaucoup d’essais, d’expérimentations. La situation devrait se décanter peu à peu et ces instruments trouveront leur place. Mais ce ne sera peut-être pas encore pour 2010.
L’avenir de la presse est à construire
La presse va encore subir de profonds changements. Internet a certainement joué un rôle de catalyseur dans la crise de la presse, mais ses véritables causes sont peut-être ailleurs. L’information a été dénaturée parce qu’on en a fait un produit dont on pensait qu’on pouvait le vendre comme des boîtes de conserve. C’est vrai pour l’actualité comme pour l’information culturelle. Les contenus des journaux sont devenus du easy reading: pages people et conseils d’achats, témoignages et tests psychologiques remplacent allègrement le reportage d’un journaliste d’investigation ou les critiques sur le monde de l’art. Dans le domaine de l’édition, on fait de même en tablant essentiellement sur des bestsellers. Tout cela a fait le jeu de la concurrence présente sur Internet: blogosphère, journalisme citoyen, encyclopédie collaborative. Cela d’autant plus facilement que les contributeurs sur Internet on érigé la gratuité en dogme fondamental. De fait, l’avenir du journalisme et de ses règles déontologiques nécessaires est encore difficile à percevoir. Actuellement les formes hybrides comme le Post.fr ou Rue89 sont en vogue. Elles allient vitesse de réaction, collaboration et vérification professionnelle des informations.
Certains tablent aussi sur le retour du journaliste, qui (re)deviendrait sa propre marque (comme Henry Morton Stanley ou Albert Londres, sans parler des modèles imaginaires comme Tintin). On retournerait au temps des grandes plumes. Les journalistes auraient leur propre blog, écriraient des articles pour d’autres titres et des livres.
http://bruxelles.blogs.liberation.fr/coulisses/2009/09/mon-avenir-estil-de-devenir-une-marque-.html
Une autre hypothèse serait la création de plateformes comparables à iTunes où les utilisateurs pourrait télécharger des articles contre des sommes minimes ou un abonnement. Le micro-payement constituerait (peut-être) une solution au problème lancinant du financement de la presse.
http://www.journalismonline.com/
Good enough revolution
C’est peut-être l’une des tendances qui est apparue au grand jour cette année, même si elle existait sur Internet depuis longtemps. La thèse principale de cet article de la revue Wired est la suivante: les utilisateurs ne recherchent pas les meilleures solutions, mais se contentent de ce qui marche. Ils téléphonent avec Skype, même si le son n’est pas optimal. Ils regardent des vidéos sur You Tube et vont moins au cinéma (mais ils iront peut-être pour Avatar). Ils achètent des Netbooks. Bref, le porte-monnaie est peut-être devenu le critère fondamental de choix, tant que le résultat est là.
http://www.wired.com/gadgets/miscellaneous/magazine/17-09/ff_goodenough
Le web sémantique
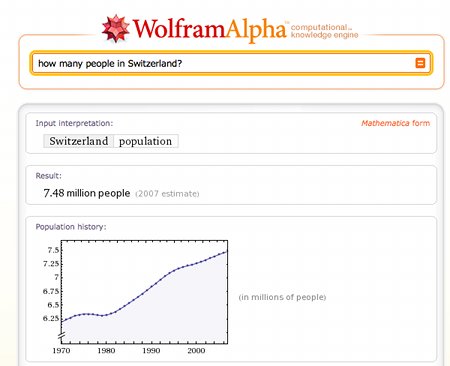
Cette année est apparu Wolfram Alpha. Ce moteur de recherche a popularisé une fonctionnalité que l’on trouvait déjà sur quelques sites: un moteur de recherche qui répond directement aux questions, sans donner une liste de liens qu’il faut encore ouvrir les uns après les autres. Désormais ce n’est plus à l’utilisateur de rechercher lui-même des réponses à ses questions. Les nouvelles générations de moteur de recherche devront les lui fournir. Pour cela, ils devront exploiter les données et les métadonnées présentes sur Internet. Ils devront aussi comprendre le langage de l’utilisateur. Ils devront aussi lui donner des réponses contextuelles, liées à sa position géographique par exemple. L’utilisateur aura accès directement aux informations nécessaires là où il est, quand il en a besoin.
En conclusion …

Dans le futur, j’accèderai à Internet grâce à un petit appareil de rien du tout dans ma poche. Il me coûtera un peu d’argent, chaque mois ou à chaque transaction. Quand j’aurai besoin d’une information (et même si je ne la demande pas), elle me parviendra en tenant compte du contexte. Quand j’arriverai à la gare, mon petit appareil me signalera des grèves. Si je prends l’avion pour un pays lointain, il m’informera d’un coup d’état. Quand je ferai les magasins, il me dira si le prix indiqué est trop élevé. Si je suis d’accord, il règlera lui-même la note. Quand je passerai devant la maison natale d’un grand homme, il me donnera sa biographie. Il me dira même qu’un de mes potes se promène dans les alentours.
Mais ce petit appareil ne sonnera pas quand passera devant moi l’homme de ma vie ou si ma voisine fait un malaise. Il me dira peut-être des choses stupides, comme de faire demi-tour dans un tunnel. Il ne remplacera pas mes amis. Il me donnera le nom d’un peintre devant un tableau, mais il ne saura pas me dire pourquoi cette peinture est belle. Avec lui, je me sentirai seule.
Bonne année 2010