
Internet contient maintenant des milliards de documents: pages HTML, images, fichiers de texte, sons, vidéos, etc. Les moteurs de recherche permettent d’indexer cette masse. Cependant il est difficile d’ordonner les différents résultats afin que l’utilisateur soit satisfait de la réponse. Google utilise par exemple le critère des liens entrants: plus une page est liée, plus elle apparaîtra haut dans la liste. C’est pourquoi nous avons souvent l’impression de tomber sur le bon site en faisait une recherche dans Google: ce sont les sites les plus populaires qui viennent en premier. Mais qu’en est-il de tous les fichiers qui composent les sites Web. Prenons une personne qui recherche une image de pommier. Il en existe des centaines de milliers. Mais comment offrir les images les plus intéressantes dans la première page de résultats? Flickr gère plus de trois milliards d’images, ce qui rend le tri assez ardu. Son équipe de développement s’est penchée sur la question et elle y a répondu par le concept d’interestingness. On relève les traces d’activités autour de l’image: clic, choix comme favori, commentaires, etc. Grâce à cela, on arrive à mettre en évidence des images intéressantes. Le résultat est rarement décevant:
http://www.flickr.com/explore/interesting/
http://www.flickr.com/explore/interesting/2009/10/
Pour obtenir ce résultat, on n’a pas seulement eu recours à l’ordinateur. On a aussi utilisé l’activité humaine. En effet, un ordinateur, si puissant soit-il, ne peut déterminer ce qui est beau ou intéressant.
Luis von Ahn, chercheur à la Carnegie Mellon University, se penche sur cette question depuis des années. Il est persuadé par l’idée que les ordinateurs sont limités et qu’ils ne pourront jamais effectuer certaines tâches qui sont simples pour le cerveau humain. C’est lui qui a lancé le fameux ESP game, qui permettait d’attribuer des mots-clés à des images. Deux partenaires, mis ensemble par hasard, doivent attribuer des mots-clés (ou tags) à des images. Si les mots-clés des deux joueurs correspondent, des points sont attribués à chacun. Les joueurs cumulent les points de toutes les parties qu’ils jouent: à celui qui en obtient le plus. Attention, le jeu est plus addictif qu’il en a l’air. Google a repris ce jeu et l’a intégré à Google Images sous la forme du Google Image Labeler:
http://images.google.com/imagelabeler/
Luis von Ahn a continué de développer ses idées à travers d’autres jeux. On les trouve tous maintenant sur un site intitulé GWAP: games with a purpose.
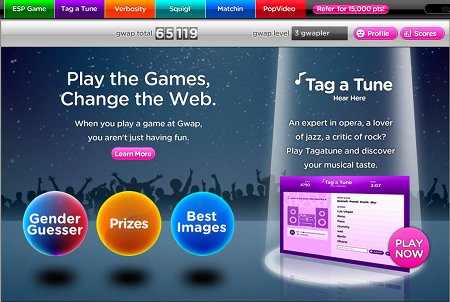
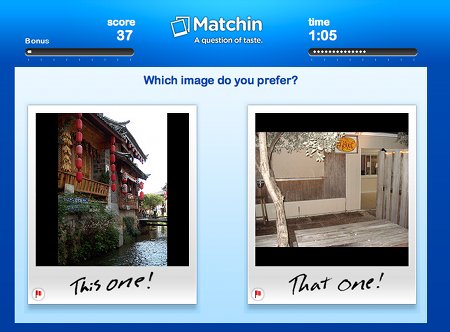
Il s’agit de véritables jeux où les participants accumulent des scores: les points glanés dans les différents jeux s’additionnent. Le but de ces jeux est d’ajouter aux documents soumis différentes métadonnées. On retrouve donc l’ESP Game. Avec Tag a Tune, les deux joueurs écoutent un morceau de musique qu’ils doivent caractériser. En lisant les mots-clés de l’autre, chaque joueur doit essayer de deviner si tous deux écoutent le même morceau. Le but est donc d’attribuer des tags à des morceaux de musique. Verbosity offre tour à tour à chacun des joueur un terme: l’un doit le caractériser, tandis que l’autre le devine. Visiblement, il s’agit d’établir des associations de termes. Avec Squigl, chacun des partenaire doit entourer ce qui correspond à un terme donné sur une image: le jeu indique “ours” et le joueur doit entourer l’endroit où il voit un ours sur l’image. Enfin Matchin (le plus addictif selon moi) présente à deux partenaires deux images: chacun doit indiquer celle qui lui plaît le plus. Si les deux joueurs choisissent la même image, ils reçoivent des points. S’ils optent pour la même photo plusieurs fois de suite, le nombre de point obtenus par tour augmentent. Le but de ce jeu est de mettre en avant les images de bonne qualité et d’écarter celles qui sont moins belles (comme les photos prises en fin de soirée et postées sur Facebook). On retrouve l’interestingness de Flickr.
Non seulement ces jeux sont utiles, car ils permettent d’indexer des masses énormes de documents, mais ils sont aussi basés sur la collaboration plutôt que sur l’opposition. A l’heure des jeux de type “Kill them all”, cela vaut la peine d’être mentionné.
Le site GWAP prétend aussi qu’il peut deviner votre genre avec 10 paires d’images où il faut dire celle que l’on aime le mieux. Mais ça ne marche pas à tous les coups.
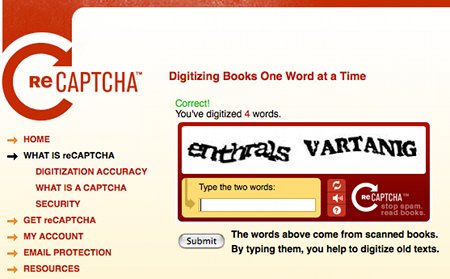
Luis von Ahn est aussi le créateur du Captcha, ce système anti-spam bien connu, évitant aux robots de placer des commentaires sur les blogs ou d’envoyer des messages par formulaire Web. Il l’a conçu dans le même esprit d’utilité et de contribution du cerveau humain à des projets informatiques. Le Captcha soumet deux images représentant des termes écrits que l’utilisateur doit retranscrire. Ces deux termes proviennent de la numérisation de livres ou de journaux. L’un des deux termes a été reconnu correctement par le programme de reconnaissance de caractères (OCR), alors que l’autre a été mal lu (le logiciel d’OCR étant capable de reconnaître ses erreurs). L’utilisateur ignore lequel des deux mots est correcte. S’il transcrit correctement le terme qui a été lu de manière juste par l’ordinateur, le système part de l’idée que le second est aussi juste. Les couples de terme sont soumis plusieurs fois et si on obtient toujours le même résultat, la lecture “humaine” est validée. Ce système est utilisé pour améliorer la numérisation d’ouvrages qui sont intégrés aux Internet Archives. Le nombre de transactions quotidiennes passant par le Captcha étant de 200 millions, l’amélioration de la numérisation est donc réelle.
Page de Luis von Ahn sur le site de la Carnegie Mellon University
A travers ces exemples remarquables, comme dans les réseaux sociaux, on sent l’imbrication de plus en plus grande entre cerveau électronique et cerveau biologique. Chacun de ces cerveaux a ses propres limites: les puces ont des puissances de calcul qui dépassent largement tout ce que nos neurones peuvent faire, mais elles ne peuvent exécuter que les tâches qui ont été programmées. Le cerveau humain a des compétences que jamais un ordinateur n’aura: imagination, conscience. En revanche, il peut utiliser les machines pour augmenter certaines fonctions: on songe en premier lieu à la mémoire.
Cette proximité toujours plus grande entre l’homme et la machine doit nous faire un peu réfléchir. Il devrait toujours revenir à l’homme de déterminer le partage des tâches. Et cela passe par une connaissance du fonctionnement d’un ordinateur auquel on a tendance à accorder trop d’intelligence et donc le développement, à large échelle, d’une culture informatique à ne pas confondre avec des compétences dans l’utilisation de l’informatique.

