
Avant que la technologie ne permette de numériser les manuscrits les plus rares et les plus fragiles, l’accès à ces documents n’était possible qu’à de rares privilégiés, qui ont passé tous les obstacles imaginables et obtenu les autorisations nécessaires. Aujourd’hui, les manuscrits sont lisibles directement sur Internet. Des fonctionnalités sophistiquées permettent de les parcourir et de les agrandir. Les chercheurs du monde entier peuvent y accéder sans mettre de gants ou signer de décharge, de même que les amateurs de littératures souhaitant connaître mieux les auteurs qu’ils admirent. Le King’s College vient de mettre en ligne les manuscrits de l’écrivain anglaise Jane Austen (1775-1817). Ces manuscrits témoignent de l’ensemble de l’oeuvre de Jane Austen, de ses jeunes années jusqu’à sa mort. Ils proviennent d’une collection restée dans la famille de l’auteur, jusqu’au décès de la soeur de Jane. Ensuite de quoi, ils ont été dispersés dans plusieurs bibliothèques. Leur numérisation permet de les réunir à nouveau. Le matériel photographique utilisé est le même que celui qui a servi à la numérisation des manuscrits de la Mer Morte. Chaque saisie dure environ 2 minutes.
http://www.janeausten.ac.uk
Parallèlement, une transcription diplomatique (c’est-à-dire respectant l’orthographe, la ponctuation, les lettres majuscules et minuscules, les mots biffés, les annotations) a été réalisée. Ce texte est disponible en format XML, permettant d’indiquer dans des balises les différentes particularités du texte, par exemple les variantes orthographiques. C’est le standard du Text Encoding Initiative (TEI) qui a été utilisé pour la mise en forme de cette transcription. Une édition imprimée est également prévue.
http://www.tei-c.org
L’étude des manuscrits des auteurs est essentielle pour le travail d’édition d’une oeuvre. Elle permet aussi de comprendre comment un auteur élabore son texte: ce dernier peut faire l’objet de nombreuses corrections ou être écrit sans rature. Le manuscrit permet aussi de découvrir quelques surprises. A en croire une experte de l’Université d’Oxford, Jane Austen était mauvaise en orthographe, en ponctuation et en grammaire, ce qui laisse supposer l’intervention d’un correcteur.
Jane Austen, sa piètre orthographe et son relecteur de talent, Le Monde (24.10.2010)
Catégorie : Bibliothèque virtuelle
Catégories
Livre ou reader?
Les vacances constituent un excellent temps pour la lecture. Après la sortie de l’iPad, on peut se demander dans quel format lire le roman de l’été: en format poche ou sur reader? Une récente étude du gourou de l’ergonomie Web, Jakob Nielsen, montre qu’il faut entre 6 à 10% de temps supplémentaire pour lire un texte (en l’occurrence une nouvelle d’Ernest Hemingway) sur un reader (iPad ou Kindle), par rapport au temps nécessaire pour la même histoire dans un livre papier. Malgré tout, les participants à l’étude se sont déclarés satisfaits par la tablette en question.
Article sur CNN
Photo: MicMac1 (Flickr)
Je suis en train d’apprivoiser mon propre iPad. J’ai commencé par charger de nombreux ouvrages provenant du domaine public. Parmi eux, le Rouge et le Noir qui fait plusieurs centaines de pages. La lecture d’un roman semble fastidieuse sur le iPad et un format de poche me paraît plus agréable. Il en va autrement pour la poésie. Un poème se lit vite. L’application iBooks permet de rechercher un mot dans tout l’ouvrage, dans un dictionnaire (le français n’est pas encore disponible), sur Internet. Il est possible de mettre des passages en évidence avec différentes couleurs et d’ajouter des notes. Sans parler de la fonction copier-coller qui permet de publier un extrait dans un blog.
L’application Kindle d’Amazon, disponible pour PC, Mac, iPhone, iPad, présente encore d’autres avantages. Tout d’abord, il est possible d’avoir ses ouvrages sur plusieurs appareils. L’état de la lecture est synchronisé entre les différentes machines. Je peux lire un ouvrage sur mon iPad lorsque je suis dans un train. De retour chez moi, je reprends ma lecture sur un ordinateur et je me retrouve exactement à la page où j’en étais arrivée. L’application Kindle permet aussi de voir combien de personnes ont mis en évidence certains passages. Il est possible de voir rapidement les passages intéressants d’un essai. On peut parler de lecture collective.
Quand on dit livre, on pense roman, Proust, Balzac, Zola. Ces textes-là, on a de la peine à s’imaginer les lire sur un reader. Il en va de même du roman de l’été: on ne va pas embarquer le dernier Marc Lévy sur son iPad et le lire sur une plage. Pourtant il n’y a qu’à jeter un œil sur sa bibliothèque pour constater qu’il existe de nombreux types de livres qu’on ne lit pas de manière linéaire. Que l’on songe aux dictionnaires, aux guides de voyage, aux manuels en tout genre, aux livres de cuisine. On peut parler de lecture utilitaire. Ce sont précisément ces ouvrages qui se prêtent le mieux à une transposition sur iPad. J’ai justement acheté un livre de recettes culinaires. Je peux chercher des recettes par mots clés (que faire avec des pommes ?), par thème (Noël). Je peux établir une liste d’achats pour un menu. Une partie des recettes et certaines actions (découper une langoustine) sont présentées sous forme de vidéos. Les recettes sont prévues pour 4 personnes. Je peux ajouter ou enlever des convives et l’application recalcule les quantités dont j’ai besoin. Seul inconvénient: il faut faire attention à son iPad sur la surface de travail …
Les readers sont conçus pour un autre type de lecture que celle d’un roman. Une lecture qu’on pourrait qualifier de discursive. Ils permettent d’annoter, de rechercher. Ils donnent de nouveaux accès à l’information, comme la géolocalisation pour les guides de voyage. On ne le dira jamais assez, les livres de papier ne disparaîtront pas. Les readers s’ajoutent à de nombreux dispositifs permettant de lire et d’accéder à la connaissance. J’ai un laptop, un iPhone, un iPad et je croule sous les livres de papier …
En cette période où la mer est mise à mal par une marée noire qui est certainement l’une des plus grandes catastrophes écologiques de notre planète, il est peut-être bon de s’intéresser à la richesse de la vie sous-marine. Le Smithsonian nous en donne l’occasion, grâce à un site lancée par le Musée national d’histoire naturel. Il s’agit d’un portail consacré à l’océan. Il présente divers aspects de la mer sous une forme attractive, avec de nombreuses images, vidéos et animations. Il montre le travail de chercheurs et offre aussi des ressources pour les enseignants.
Il offre également une perspective chronologique de la vie sous-marine, à travers des timelines. L’un montre l’évolution des cétacés et l’autre les grands prédateurs marins.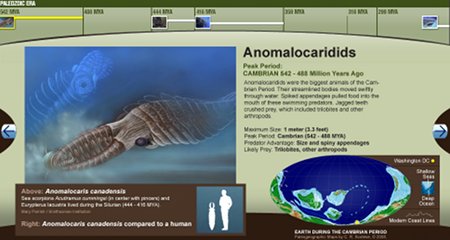
http://ocean.si.edu/
Depuis ce matin, j’assiste à la Conférence Lift10 à Genève. La journée a commencé par des workshops. Je me suis inscrite à l’atelier animé par Frédéric Kaplan sur les nouveaux supports de lecture. Plusieurs groupes ont essayé d’imaginer des scénarios de lecture: comment certains contenus (magazine, manuel, guide de voyage, histoire pour enfants, etc … ) peuvent être lus sur différents supports (smartphones, tablettes, tableau interactif, etc … ) ?
Dans plusieurs des projets élaborés au cours de cet atelier, la lecture devenait non seulement interactive, mais elle supposait aussi des échanges avec d’autres personnes, proches ou distantes. Pendant longtemps la lecture a été considérée comme une activité solitaire, même si cela n’a pas toujours été le cas, comme en témoignent des exemples à travers l’histoire de lectures en public ou dans le cadre familiale. Les nouveaux supports invitent au partage des lectures, car ils sont connectés à Internet. La lecture (re)deviendrait-elle une activité sociale ?
Parmi les combinaisons contenus-supports plébiscitées par l’audience, on peut mentionner les guides de voyage sur des tableaux ou tablettes, les journaux sur tablettes et les magazines avec codes barres. L’avenir nous dira si elle a raison.
Internet contient maintenant des milliards de documents: pages HTML, images, fichiers de texte, sons, vidéos, etc. Les moteurs de recherche permettent d’indexer cette masse. Cependant il est difficile d’ordonner les différents résultats afin que l’utilisateur soit satisfait de la réponse. Google utilise par exemple le critère des liens entrants: plus une page est liée, plus elle apparaîtra haut dans la liste. C’est pourquoi nous avons souvent l’impression de tomber sur le bon site en faisait une recherche dans Google: ce sont les sites les plus populaires qui viennent en premier. Mais qu’en est-il de tous les fichiers qui composent les sites Web. Prenons une personne qui recherche une image de pommier. Il en existe des centaines de milliers. Mais comment offrir les images les plus intéressantes dans la première page de résultats? Flickr gère plus de trois milliards d’images, ce qui rend le tri assez ardu. Son équipe de développement s’est penchée sur la question et elle y a répondu par le concept d’interestingness. On relève les traces d’activités autour de l’image: clic, choix comme favori, commentaires, etc. Grâce à cela, on arrive à mettre en évidence des images intéressantes. Le résultat est rarement décevant:
http://www.flickr.com/explore/interesting/
http://www.flickr.com/explore/interesting/2009/10/
Pour obtenir ce résultat, on n’a pas seulement eu recours à l’ordinateur. On a aussi utilisé l’activité humaine. En effet, un ordinateur, si puissant soit-il, ne peut déterminer ce qui est beau ou intéressant.
Luis von Ahn, chercheur à la Carnegie Mellon University, se penche sur cette question depuis des années. Il est persuadé par l’idée que les ordinateurs sont limités et qu’ils ne pourront jamais effectuer certaines tâches qui sont simples pour le cerveau humain. C’est lui qui a lancé le fameux ESP game, qui permettait d’attribuer des mots-clés à des images. Deux partenaires, mis ensemble par hasard, doivent attribuer des mots-clés (ou tags) à des images. Si les mots-clés des deux joueurs correspondent, des points sont attribués à chacun. Les joueurs cumulent les points de toutes les parties qu’ils jouent: à celui qui en obtient le plus. Attention, le jeu est plus addictif qu’il en a l’air. Google a repris ce jeu et l’a intégré à Google Images sous la forme du Google Image Labeler:
http://images.google.com/imagelabeler/
Luis von Ahn a continué de développer ses idées à travers d’autres jeux. On les trouve tous maintenant sur un site intitulé GWAP: games with a purpose.
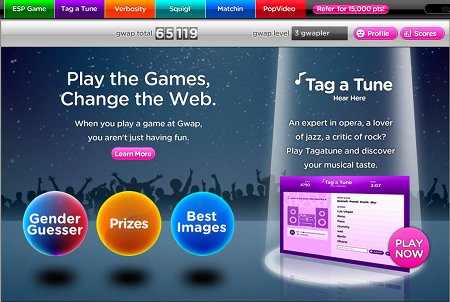
Il s’agit de véritables jeux où les participants accumulent des scores: les points glanés dans les différents jeux s’additionnent. Le but de ces jeux est d’ajouter aux documents soumis différentes métadonnées. On retrouve donc l’ESP Game. Avec Tag a Tune, les deux joueurs écoutent un morceau de musique qu’ils doivent caractériser. En lisant les mots-clés de l’autre, chaque joueur doit essayer de deviner si tous deux écoutent le même morceau. Le but est donc d’attribuer des tags à des morceaux de musique. Verbosity offre tour à tour à chacun des joueur un terme: l’un doit le caractériser, tandis que l’autre le devine. Visiblement, il s’agit d’établir des associations de termes. Avec Squigl, chacun des partenaire doit entourer ce qui correspond à un terme donné sur une image: le jeu indique “ours” et le joueur doit entourer l’endroit où il voit un ours sur l’image. Enfin Matchin (le plus addictif selon moi) présente à deux partenaires deux images: chacun doit indiquer celle qui lui plaît le plus. Si les deux joueurs choisissent la même image, ils reçoivent des points. S’ils optent pour la même photo plusieurs fois de suite, le nombre de point obtenus par tour augmentent. Le but de ce jeu est de mettre en avant les images de bonne qualité et d’écarter celles qui sont moins belles (comme les photos prises en fin de soirée et postées sur Facebook). On retrouve l’interestingness de Flickr.
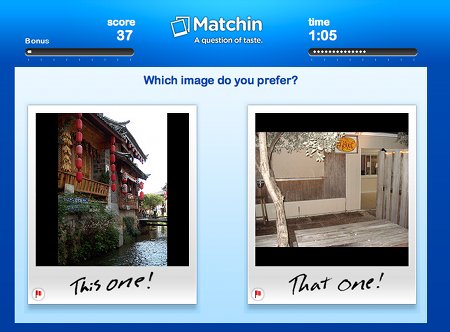
Non seulement ces jeux sont utiles, car ils permettent d’indexer des masses énormes de documents, mais ils sont aussi basés sur la collaboration plutôt que sur l’opposition. A l’heure des jeux de type “Kill them all”, cela vaut la peine d’être mentionné.
Le site GWAP prétend aussi qu’il peut deviner votre genre avec 10 paires d’images où il faut dire celle que l’on aime le mieux. Mais ça ne marche pas à tous les coups.
Luis von Ahn est aussi le créateur du Captcha, ce système anti-spam bien connu, évitant aux robots de placer des commentaires sur les blogs ou d’envoyer des messages par formulaire Web. Il l’a conçu dans le même esprit d’utilité et de contribution du cerveau humain à des projets informatiques. Le Captcha soumet deux images représentant des termes écrits que l’utilisateur doit retranscrire. Ces deux termes proviennent de la numérisation de livres ou de journaux. L’un des deux termes a été reconnu correctement par le programme de reconnaissance de caractères (OCR), alors que l’autre a été mal lu (le logiciel d’OCR étant capable de reconnaître ses erreurs). L’utilisateur ignore lequel des deux mots est correcte. S’il transcrit correctement le terme qui a été lu de manière juste par l’ordinateur, le système part de l’idée que le second est aussi juste. Les couples de terme sont soumis plusieurs fois et si on obtient toujours le même résultat, la lecture “humaine” est validée. Ce système est utilisé pour améliorer la numérisation d’ouvrages qui sont intégrés aux Internet Archives. Le nombre de transactions quotidiennes passant par le Captcha étant de 200 millions, l’amélioration de la numérisation est donc réelle.
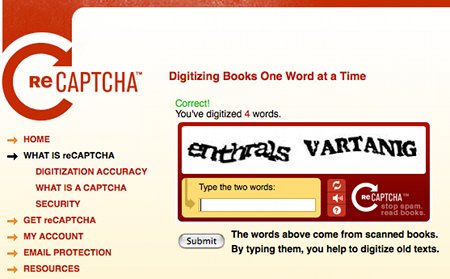
Page de Luis von Ahn sur le site de la Carnegie Mellon University
A travers ces exemples remarquables, comme dans les réseaux sociaux, on sent l’imbrication de plus en plus grande entre cerveau électronique et cerveau biologique. Chacun de ces cerveaux a ses propres limites: les puces ont des puissances de calcul qui dépassent largement tout ce que nos neurones peuvent faire, mais elles ne peuvent exécuter que les tâches qui ont été programmées. Le cerveau humain a des compétences que jamais un ordinateur n’aura: imagination, conscience. En revanche, il peut utiliser les machines pour augmenter certaines fonctions: on songe en premier lieu à la mémoire.
Cette proximité toujours plus grande entre l’homme et la machine doit nous faire un peu réfléchir. Il devrait toujours revenir à l’homme de déterminer le partage des tâches. Et cela passe par une connaissance du fonctionnement d’un ordinateur auquel on a tendance à accorder trop d’intelligence et donc le développement, à large échelle, d’une culture informatique à ne pas confondre avec des compétences dans l’utilisation de l’informatique.
L’idée que le patrimoine culturel est un bien commun et que, par conséquent, chacun peut non seulement en jouir, mais aussi l’utiliser dans ses propres productions, fait son petit bonhomme de chemin. Grâce à Flickr, des institutions du monde entier peuvent mettre à disposition des documents numérisés dans le domaine public.

Ces documents peuvent être réutilisés sans restrictions. Parmi ces les institutions qui participent à ce programme, on peut mentionner:
- The Library of Congress
- Brooklyn Museum
- Smithsonian Institution
- Bibliothèque de Toulouse
- Bibliothèque de la Fondation Calouste Gulbenkian
- Musée McCord Museum
- Nationaal Archief (Pays-Bas)
- New York Public Library
- Swedish National Heritage Board
- Llyfrgell Genedlaethol Cymru – The National Library of Wales
- Getty Research Institute
Non seulement on peut réutiliser ces images, mais on est aussi invité à les commenter et à proposer des mots-clés, donc à les enrichir.
Une nouvelle bibliothèque numérique à vocation universelle vient de s’ouvrir sur le Net: la Bibliothèque numérique mondiale. Elle veut mettre à disposition des contenus multi-culturels, notamment dans un but éducatif et en vue de réduire la fracture numérique. Elle a été créée par l’UNESCO et la Bibliothèque du Congrès, en collaboration avec d’autres partenaires.
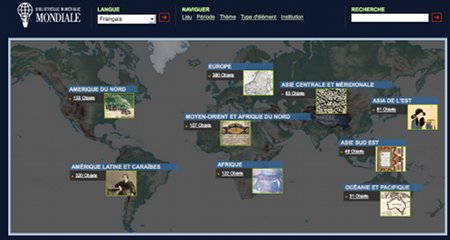
Pour l’instant, elle ne compte que 1170 objets: des livres, des revues, des manuscrits, des cartes, des films, des gravures, des photographies et des enregistrements sonores. Ces documents proviennent de diverses époques, de l’Antiquité à nos jours, et de tous les continents. Ils peuvent être recherchés par lieu, par période, par thème, par type d’élément, par institution.
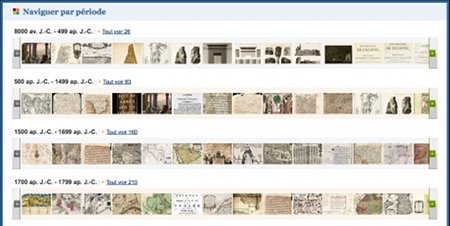
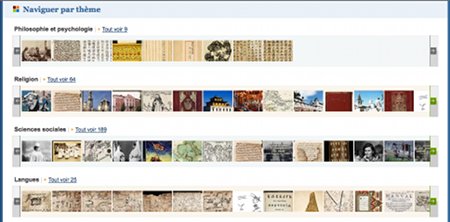
La bibliothèque numérique dispose aussi d’un outil de visualisation permettant de naviguer à l’intérieur des documents et pourvu d’une fonctionnalité de zoom que l’on peut activer avec la roulette de la souris.
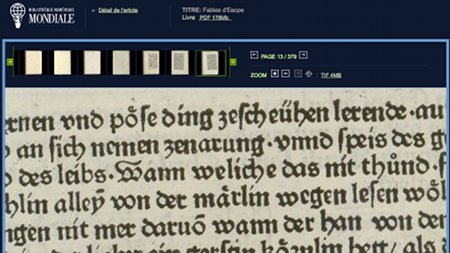
Le moteur de recherche permet d’affiner les résultats grâce à des méta-données. Des boutons permettent de partager les diverses ressources sur des sites de social bookmarking.
Espérons que cette bibliothèque s’enrichira rapidement …
Catégories
Bible virtuelle
Etrange histoire que celle de cette version de la bible, retrouvée par hasard par un savant au fond d’une corbeille à papier du Monastère Saint-Catherine, dans le Sinaï. Considérée comme de peu de valeur, le manuscrit a été démembré et, après divers aléas, s’est retrouvé dans 4 différents endroits: la British Library , la bibliothèque nationale de Russie , la bibliothèque de l’Université de Leipzig, le Monastère St. Catherine. Internet devient donc la seule possibilité de le réunir. Les différentes bibliothécaires propriétaires de parties du manuscrit ont donc décidé de mettre sur pied un projet de numérisation. La première partie des pages, celles qui se trouvent à Leipzig, sont en ligne depuis aujourd’hui:
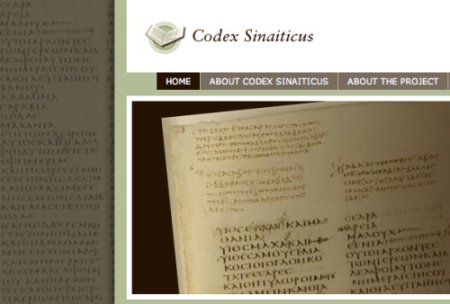
http://www.codex-sinaiticus.net/
Le battage médiatique ayant été bien orchestrée, le manuscrit était difficilement accessible ce soir.
Catégories
Remonter le Times
Le célèbre quotidien anglais vient de mettre l’ensemble de ses archives numérisées en ligne, des archives qui remontent à 1875. Il est désormais possible de lire des articles tels qu’ils apparurent à des lords anglais qui les découvraient dans un journal en papier parfaitement repassé par leur valet.
La page d’entrée offre une frise chronologique permettant de trouver des événements marquants durant plus de deux siècles. Pêle-mêle, on y trouve la décapitation de la reine Marie-Antoinette, la bataille de Waterloo, l’assassinat du Président Lincoln, etc. On peut accéder ensuuite à l’article dans la mise en page de l’époque, avec un repère indiquant où se trouve l’article sur la place. La rédaction a également préparé quelques dossiers thématiques, comme l’histoire de la famille royale, le Titanic ou encore Jack l’Eventreur.
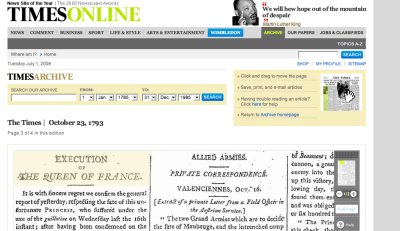
http://archive.timesonline.co.uk/tol/archive/
Pour l’instant, ces archives sont gratuites. Quelques articles sont en accès totalement libre et pour les autres, il suffit d’ouvrir un compte gratuit. Espérons que cela reste ainsi.
Internet est devenu en quelques années la plus grande masse de données réunie de manière relativement homogène et accessible. Jamais jusqu’alors dans l’histoire de l’humanité, l’accès aux connaissances n’a été aussi aisé de même que leur remixage. Tous ces contenus numérisés peuvent être copiés, retravaillés, trouvés par des moteurs de recherche. La question de la conservation de ces données se pose maintenant, notamment pour les contenus numériques natifs. Cet archivage est très complexe pour plusieurs raisons:
- les sites Internet changent très souvent
- les formats des données évoluent sans cesse de même que les logiciels, les supports et les appareils (software, hardware)
- les volumes nécessaires pour la conservation coûtent très chers, surtout si on souhaite un historique des données
Mais est-il nécessaire de conserver l’ensemble des données disponibles sur Internet? D’une part, tout archivage suppose un tri. Tout n’est pas digne d’archivage. Chaque société est amené à faire des choix dans ce domaine. Bien entendu, c’est risqué car même les critères de choix évoluent. Les historiens s’intéressaient d’abord aux documents officiels, mais cette discipline s’est penchée plus récemment sur la vie quotidienne des populations dont la documentation n’a pas été systématiquement archivée. Il en sera de même pour Internet: qui archivera les centaines de milliers de blogs personnels? Ils pourraient cependant constituer des témoignages intéressants pour des historiens, des sociologues, des linguistes. La lacune n’est du reste pas le pire des maux et bien des méthodes permettent d’en dessiner les traits.
Pour tempérer un peu la crainte de perdre ces données réunies en masse, essayons à nouveau de nous pencher sur le passé. L’incendie de la Bibliothèque d’Alexandrie est considéré comme une des catastrophes majeure de l’Antiquité. Pourtant ce drame doit être remis dans son contexte. Cette institution a été créée par Ptolémée 1er, premier roi grec d’Egypte à la fin du 3ème siècle avant J.-C.. Première constatation, il s’agit bien d’une volonté politique. Ensuite, cette institution ne se limitait pas à une bibliothèque: le Museion accueillait aussi des savants prestigieux qui devaient exploiter la bibliothèque. Quant à la bibliothèque elle-même, tout avait été mis en place pour l’enrichir. Les bateaux abordant dans le port d’Alexandrie devaient remettre leurs documents pour qu’ils soient copiés. La copie était rendue au capitaine et l’original conservé à la Bibliothèque.
La Bibliothèque d’Alexandrie n’était pas un cas unique: toutes les grandes cités de la période hellénistique avait la leur. Il y avait même une émulation, voire une concurrence entre toutes ces bibliothèques. On essayait par exemple d’acquérir des collections d’ouvrages ou d’attirer les meilleurs savants. La principale concurrente d’Alexandrie était Pergame. On raconte que les Alexandrins avaient refusé d’exporter du papyrus égyptien vers Pergame pour mettre à mal les activités de sa bibliothèque. Les gens de Pergame ont donc essayé de trouvé un autre support pour écrire et ont donc inventé le parchemin, fabriqué à partir de peau de bête. Le mot parchemin vient du nom de Pergame et ce support s’imposera au Moyen Âge.
Que constate-t-on durant la période hellénistique? Une circulation et une diffusion importante des connaissances doublée d’une grande activité intellectuelle. Grâce à toutes ces bibliothèques, on a pu faire une synthèse de la culture grecque (en incluant même des cultures voisines). On a revisité les auteurs anciens. Aucune de ces bibliothèques n’a survécu au temps, ni celle d’Alexandrie, ni celle de Pergame. Peu importe donc que César lui ait bouté le feu. L’essentiel est en fait que ces bibliothèques ont existé, que les connaissances et les idées ont circulé. Grâce à cela, nous avons pu conserver des connaissances qui auraient été perdues autrement. Bien entendu, on peut regretter que les savants hellénistiques aient fait des sélections comme les pièces des Tragiques qui méritaient de passer à la postérité. Sans eux cependant, on aurait peut-être perdu l’ensemble de ces oeuvres.

Bibliothèque romaine privée
Crédit : http://www.vroma.org/
N’assiste-t-on pas à un phénomène analogue aujourd’hui? De plus en plus de connaissances sont maintenant accessibles et les efforts de numérisation continuent. En même temps, ces connaissances font l’objet de discussions, de commentaires, de synthèses, de recompositions, d’indexation. Ce qui nous distingue de l’époque hellénistique, c’est le nombre de personnes qui ont accès à ces connaissances, parce qu’elles savent lire et qu’elles ont un appareil leur permettant d’y accéder à disposition. Il y a là un formidable catalyseur de découvertes, de progrès scientifiques, ce d’autant plus que les outils que nous avons à disposition facilitent la collaboration et le partage. C’est ce phénomène qui mérite d’être reconnu aux yeux des générations futures.
Nous avons regardé dans le passé. Plongeons-nous dans le futur maintenant, mais dans celui de la science-fiction. Dans son cycle Fondation, Isaac Asimov pose une question intéressante. Son personnage, Hari Seldon, montre que les civilisations connaissent des cycles de mort et de renaissance. Grâce à une science qu’il a développé, la psychohistoire, il parvient à calculer l’intervalle entre la mort prochaine de sa propre civilisation et celle qui lui succédera. Comme cet intervalle est long (30′000 ans), il se demande comment le réduire. C’est ainsi qu’il crée aux confins du monde deux fondations formées de savants qui ont pour tâche de rédiger l’Encyclopedia Galactica. Cela n’est pas sans rappeler le rôle des Monastères du Moyen-Âge qui ont thésaurisé des connaissances de l’Antiquité pour le plus grand bénéfice de notre culture.
Pour revenir à la question de l’archivage, on voit bien que l’exhaustivité n’est pas requise. Un processus de sélection doit intervenir, qu’il se fasse par un choix conscient ou sui generis (ou une solution hybride). Nous n’en sommes peut-être pas encore là. Pour l’instant, il s’agit de tout mettre sur la table, de faire l’inventaire de nos connaissances, de rediscuter peut-être les critères qui nous permettent de qualifier ces connaissances.