Un des grands chantiers du Web, c’est l’indexation des contenus. Cela signifie que chaque objet d’information: page web, fichier graphique, document, doit recevoir des mots-clés. Dans une banque de données restreinte comme un catalogue de musée ou de bibliothèque, c’est déjà une entreprise délicate. Mais à l’échelle d’Internet, c’est une tâche titanesque. Pourtant la nécessité est claire, si l’on souhaite accéder à l’ensemble des ressources via un moteur de recherche. Les éléments comportant du texte peuvent être indexés et livrer ainsi quelques mots-clés (même si ce n’est pas forcément les termes par lesquels les gens les chercheront). Les images continuent à poser un problème. Les moteurs de recherche d’images fonctionnent habituellement en indexant le nom du fichier et le contenu de la page où l’image est intégrée. Les images étant par nature complexes, on n’obtient pas forcément les mots-clés adéquats. Le recours à l’intelligence humaine semble être encore le meilleur moyen. Mais comment indexer des masses d’images?
Cette question est posée depuis quelques temps sur Internet, notamment grâce à des sites de partage de photos comme Flickr. Sur ce site, celui qui met une image peut insérer des mots-clés. Les autres utilisateurs ont la possibilité de proposer des mots-clés complémentaires, si le propriétaire des images l’autorise.
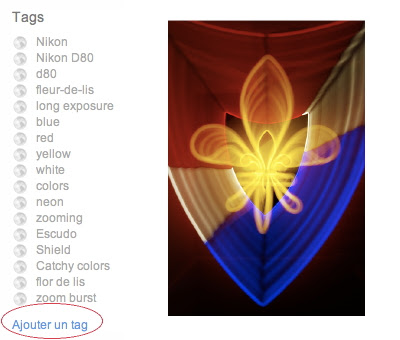
Exemple d’une image « taggable » dans Flickr
La possibilité de donner des mots-clés à des objets s’appelle le tagging, du terme anglais tag.
Pourquoi cette possibilité de donner des mots-clés alternatifs? C’est essentiel, car on sait que c’est une pratique très subjective. Celui qui a créé l’image est peut-être un connaisseur du sujet: imaginons un botaniste qui prend une photo d’une fleur. Il va en donner le nom scientifique. Mais la plupart des gens utiliseront le terme vernaculaire pour rechercher une image de cette fleur. De plus, ce terme vernaculaire peut changer d’une région à l’autre. On comprend alors l’intérêt de laisser d’autres utilisateurs proposer des mots-clés. Il y a bien entendu le risque d’avoir aussi des termes erronés ou absurdes, mais le bénéfice général est supérieur. Quand on donne la possibilité au public de proposer des mots-clés, on parle de folksonomy ou indexation populaire.
Dans le domaine des musées, on s’est intéressé à la folksonomy. Il y a des expériences en cours, comme le « Art Museum Social Tagging Project » ou Steve. Le site Web du projet présente des oeuvres d’art et des objets archéologiques ou ethnologiques à indexer. Les visiteurs peuvent proposer des mots-clés. Une première analyse des termes proposés par le public montre que 90% des termes proposés ne se trouvent pas dans la documentation du musée relative à aux objets correspondants.
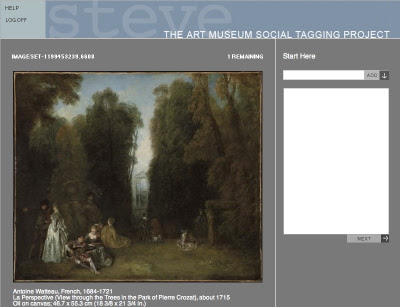
http://www.steve.museum/index.php?optio … &id=51
http://www.steve.museum/
Cela illustre bien le fossé entre l’indexation savante et les représentations populaires. Et cela fonde la nécessité de l’indexation populaire. Du reste, certains musées jouent déjà le jeu:
– http://www.clevelandart.org
– http://magart.rochester.edu/
Le recours aux foules pour indexer des masses énormes de documents correspond à deux tendances profondes et conjointes du web. Tout d’abord le Web 2.0 et la soif des internautes de participer aux contenus. Wikipédia, l’encyclopédie participative, en est l’exemple-phare. On est passé d’un internaute consommateur, content de trouver de nombreuses données en ligne, à un internaute consomm-acteur, qui souhaite contribuer aux sites qu’il visite, en commentant, en composant des textes, en intégrant des images, etc… La seconde tendance est en fait l’autre face du Web 2.0: les initiateurs de grands projets ont tôt fait de comprendre le parti qu’ils pouvaient tirer de la situation en utilisant le travail de la foule des internautes. On parle alors de « crowdsourcing », un terme forgés sur les termes « crowd » (foule » et out-sourcing. Il y en a de nombreux exemples: cela peut aller de l’utilisation de la puissance de calcul de milliers d’ordinateurs dispersés dans le monde à de la recherche médicale. Certains projets assurent même un revenus à ceux qui y participent.
En l’absence de salaire, comment convaincre les internautes d’indexer des images? Le tagging est une activité modeste et invisible (contrairement à un article dans Wikipédia). Luis von Ahn, un chercheur en informatique, a considéré que la facteur humain était essentiel dans l’informatisation et la numérisation. Il a imaginé qu’un simple jeu pouvait permettre d’indexer une masse considérable d’images. Il a mis au point ESPgame: on joue avec un partenaire attribué par le système. Chacun voit la même image et doit proposer des mots-clés dans un temps limite pour obtenir des points.
http://www.espgame.org/
Ce jeu a obtenu un grand succès et il a été repris par Google, sous le nom de Google Image Labeler:
http://images.google.com/imagelabeler/
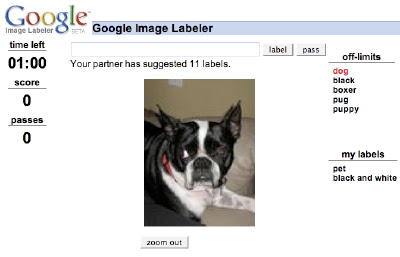
Ainsi, grâce à ce jeu simplissime et pourtant amusant (voire addictif comme tous les jeux à score), Google escompte bien indexer des masses à peine chiffrables d’images et améliorer ainsi les recherches de Google Images.
Alors que le monde physique est marqué par une tendance à l’individualisme, le monde virtuel retrouve l’esprit des bâtisseurs de cathédrale, de la participation à une tâche qui dépasse l’individu. Cet état d’esprit est fondamental pour augmenter les informations sur Internet et les consolider en les rendant plus accessibles. Il est évident que l’indexation est l’une des clés de cette consolidation et qu’elle ne peut pas être le fait d’individus ou d’équipes restreintes et hautement formées.
















 Une porte chaque jour, et gare à ceux qui se montrent trop curieux!
Une porte chaque jour, et gare à ceux qui se montrent trop curieux!